

(原标题:DeepSeek是比肩OpenAI的国产AI之光吗?)
“梁文峰以及他的团队显然是一群有“利润之上”的追求的人们。”,这是段永平在雪球平台上对DeepSeek的评价。印象中,他上一次给出这么高评价的CEO,还是对苹果乔布斯的评价。
从2024年12月16日发布DeepSeek-V3后,在美国的AI圈得到了行业专家极高的评价,比如OpenAI创始团队成员卡帕斯(Andrej Karpathy)、英伟达的高级科学家Jim Fan等等。由于影响力太大,连OpenAI的CEO 山姆·奥特曼(Sam Altman)也出来发推阴阳了几句。
一、DeepSeek的能力与OpenAI最好的模型不相上下
1. 从DeepSeek-R1论文中与ChatGPT的各项能力指标对比来看,DeepSeek(后文简称为DS)确实是中国唯一可以比肩ChatGPT的AI大模型。
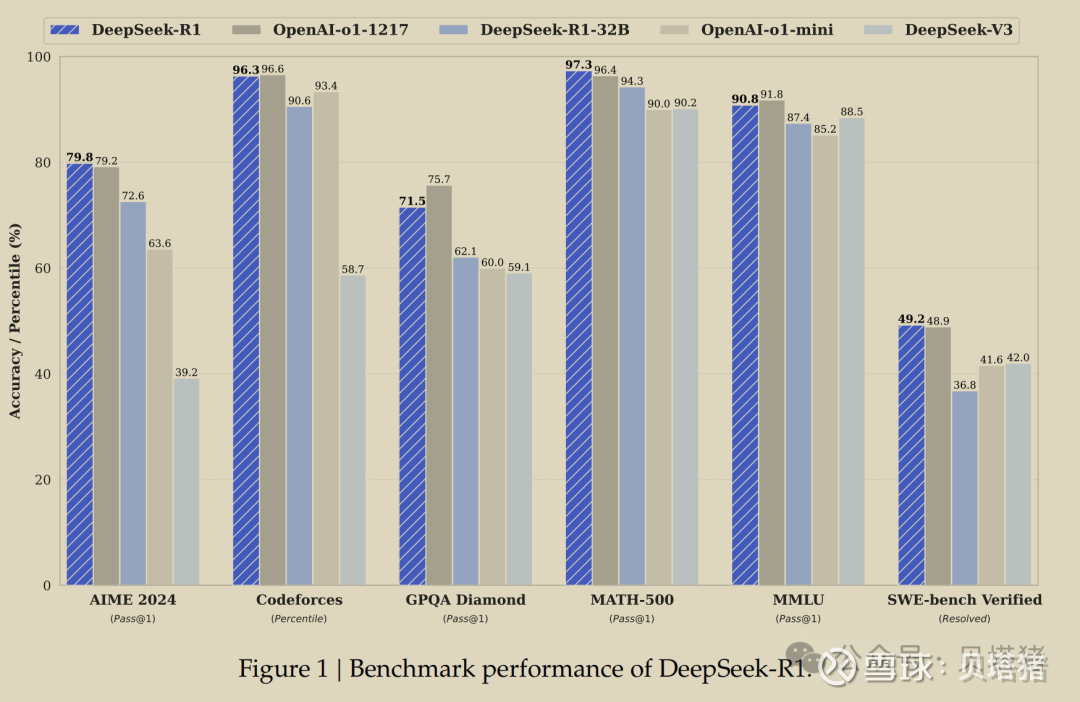
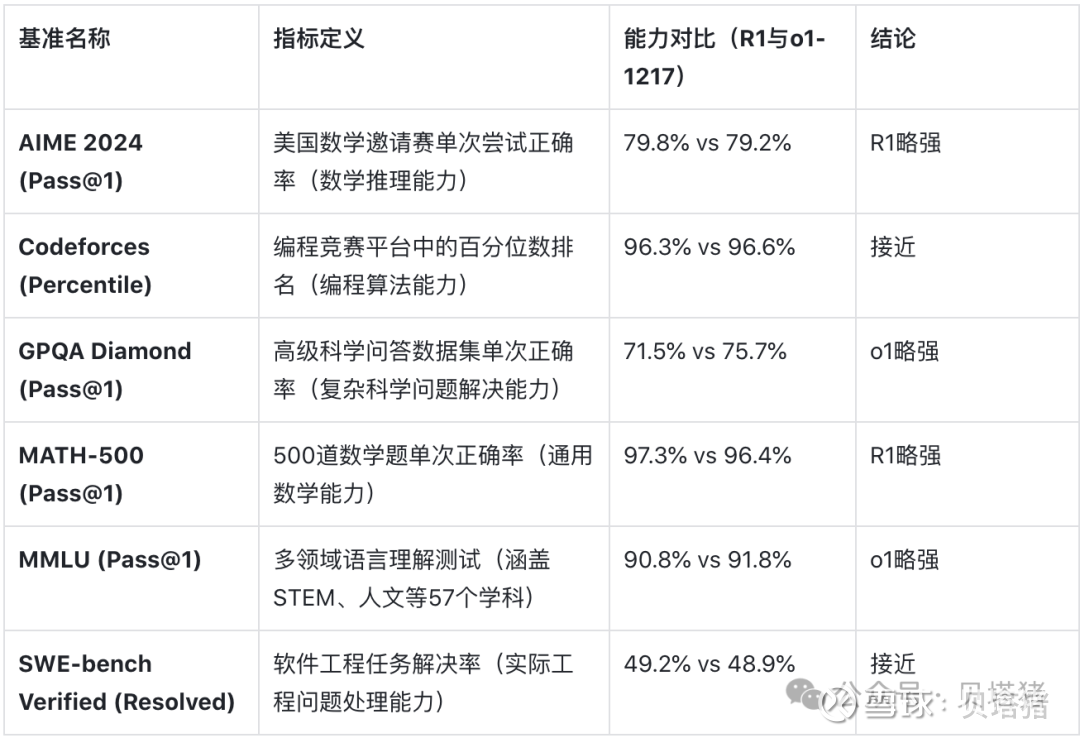
2. DS-V3的能力,在各项能力的测评上与ChatGPT-4o不相上下。
这些评测(benchmarks)是由研究人员精心设计,以衡量 AI 在 推理、数学、编程、知识问答、语言理解 等方面的能力。所以,评测结果的对比参考价值非常大。
二、DS-V3与DS-R1
上图中,在不选择深度思考(R1)时,DS默认是用V3回答的。在场景和能力上对标ChatGPT的4o。R1则对标o1,从前面的图表可以看出,R1在各项能力上都要比V3强出很多。
DS-V3 为自研 MoE 模型(专家混合模型),举个栗子说明MoE:
想象一个餐厅,有不同厨师(专家),每位擅长一种菜系(如中餐、意大利菜、甜点)。顾客点菜时,经理(门控网络)根据菜品决定由哪位厨师负责。比如点披萨,意大利菜厨师接手;点宫保鸡丁,中餐厨师处理。经理确保每道菜由最合适的厨师完成。(来源于DS-V3)
DS-R1在后训练阶段大规模使用了强化学习(RL)技术,在仅有极少标注数据的情况下(ChatGPT使用了大量的人工标注数据),极大提升了模型推理能力。举个栗子说明纯强化学习(无监督数据):
纯强化学习就像自学成才的厨师,通过不断尝试和失败,最终掌握完美煎蛋的技巧。虽然过程艰难,但一旦成功,能力将非常强大且自主。(来源于DS-V3)
三、DS在工程上做了很多创新
从各项能力的评测结果来看,开源的DS领先所有的开源模型,并且与最好的闭源模型(OpenAI的)不相上下,没有创新是不可能做得到的。技术路线和一些方法是老早就有的,但是DS在工程上做了很多创新。就像马斯克并没有发明新的火箭与新的汽车,但是他通过工程创新极大的降低了造火箭的成本,提升了造火箭的效率。在电池上也是通过工程创新极大地降低了成本,减少了与整车的成本比例。
DS在工程上的创新:1. 无监督RL训练革命:首创跳过监督微调(SFT)的纯强化学习路径,直接在基础模型上应用2. 高效蒸馏技术:通过80万条RL生成数据,将R1的推理能力蒸馏至1.5B-70B规模模型,实现小模型性能飞跃(如Qwen-32B在AIME 2024达72.6% pass@1)。(OpenAI的模型没开源,能看到的都是最终结果,这是没法蒸馏的。蒸馏需要老师模型的输出概率分布,拿学生模型的输出概率分布和老师的概率分布对比算一个KL散度损失函数,通过反向传播一步步优化学生模型的参数,目标是让学生模型的输出概率分布逐渐接近老师分布。只有最终结果没有di概率分布,你失去了绝大多数的有用信息,学不了的。AI行业专家@DrChuck )验证蒸馏效果优于直接小模型RL训练,为资源受限场景提供高效方案,推理成本降低80%。
3. 自适应MoE专家选择:动态路由算法+细粒度专家划分(128专家选2),相比密集模型减少70%计算量,长文本处理速度提升40%。
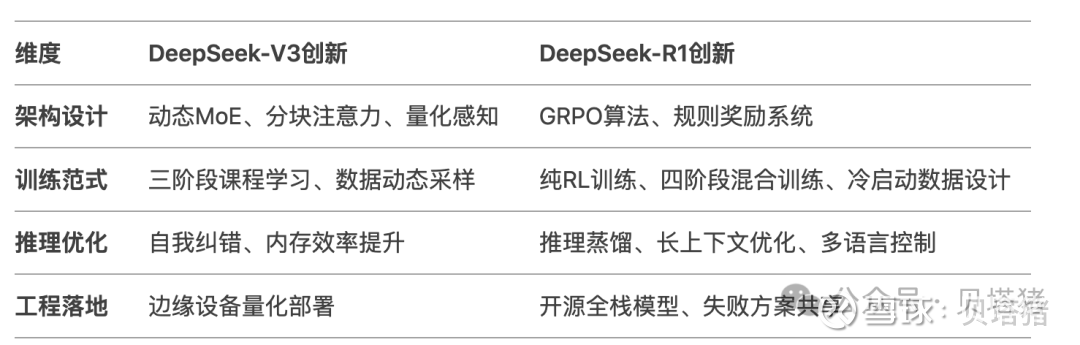
备注:以上内容是通过DS阅读V3和R1论文总结得到的。
四、DS对AI生态的影响
大模型AI的三要素:数据、算法、算力。影响最大的是算法、算力。
1.算法
DS完全开源(最强的OpenAI是闭源),由于在工程上有很多创新,无疑给中国AI大模型创业带来了胜利的曙光。印象中百度李彦宏在2024年采访中提到,中国没有机会再诞生OpenAI这样的公司,DS的出现突破了竞争格局。接下来抖音集团、腾讯、阿里等头部做大模型的公司,大概率都会随着DS的步伐跟上。
2.算力
DS-V3的训练成本仅为557万美元,约为OpenAI、谷歌等公司的几十分之一。以Llama-3.1为例,其训练需要16000张H100卡且耗时数月,而DS-V3仅使用2048张H800卡,在两个月内就完成了训练,计算量约为Lama-3.1的八分之一。推理成本方面,DS-V3的每百万token费用仅为1美元,约为GPT 4 Turbo的七十分之一。
经过工程上的创新,同等AI能力的情况下,算力成本会大幅下降。不过,训练成本的下降意味着API成本也会大幅下降,这有利于C端应用的爆发,从而刺激更大的算力需求。芯片算力上,英伟达是绝对的领先者,从英伟达建立的CUDA生态来看,在训练阶段目前仍难有替代者。DS这类大模型能否绕开英伟达的 CUDA 技术?答案是技术上可以,但实际要看具体情况。
分两个场景看:
1. 推理(使用训练好的模型):
完全可以绕开,就像手机软件换个手机也能运行。模型训练好后只是一堆参数,用国产显卡(如天数、华为)或配套软件也能正常使用,不依赖 CUDA。
2. 训练(从头教模型学习):
目前可能仍用英伟达显卡(如公开资料显示 DeepSeek 在用 H800 芯片),但技术上存在替代方案:
方案一:用国产显卡(如天数)兼容 CUDA 生态,实测可行但速度可能稍慢。
方案二:用华为显卡+自研软件(如昇腾芯片+MindSpore 框架),或适配国产硬件的 PyTorch 版本,能实现训练但需调整技术流程。
备注:以上内容是根据行业从业者发言整理的@段嘉铭
结语:
开源的DS将会给自己建立起很强的竞争壁垒,因为对于AI应用,强者几乎会占有绝大部分用户,然后在AI的三要素上循环补强。看了梁文峰的不少发言,梁文峰不仅有能力,还有很大的格局,相信在组织进化能力上也很强。
DS最好的模型都开源,训练、推理成本均大幅下降,这无疑给普通的创业者带来了巨大的机会,这个机会就好比早期的互联网创业。所以,年轻的朋友们也得抓紧时间研究起来,这样的机会绝对是几十年一遇!!!
$英伟达(NVDA)$ $腾讯控股(00700)$ $阿里巴巴(BABA)$





 首页
首页 微信公众号
微信公众号
 证券之星APP
证券之星APP




