

(原标题:行业探讨|想用大白话聊聊DeepSeek)
这两天DeepSeek爆火出圈,几乎所有媒体平台都在刷屏,A股相关概念更是迎来大涨。
本来是不太想聊,毕竟科技或者软件博主讲得会更专业,但后来发现他们讲得好像有点太专业,有些内容我都不是很看得懂。
既然DeepSeek能够撼动华尔街和硅谷,并且一举把英伟达股价都拉下来(盘前已超跌10%),很值得骄傲,那就尝试聊几句吧,试试用大白话解读。
首先,DeepSeek到底是个啥?
DeepSeek实际是英文名,这家公司中文名叫深度求索(很喜欢这个名字,做价值投资就是要深度,异曲同工),出身背景不算强势,母公司不是互联网或科技大厂,而是国内一家量化私募基金,幻方量化。
当然幻方绝不算是“小虾米”,估计球友们都不会陌生,一度是中国首家突破千亿管理规模的私募基金,业内颇有名气。
做研究要先看“人”。幻方量化及DeepSeek创始人,叫作梁文锋,出生于1980年代广东一个五线城市,本硕都就读于浙江大学,攻读人工智能专业。
这位“奇才”面貌如何?下面这张,就是梁文锋1月20日参加座谈会的央视直播画面,很年轻,而且还挺清秀。

严格来说,DeepSeek发展历史能追溯10年:
2015年,梁文锋和朋友创办幻方,立志成为世界顶级的量化对冲基金。
2016年,幻方量化推出AI模型,是第一份由深度学习生成的交易仓位。
2023年7月,梁文锋创办深度求索DeepSeek,专注于AI大模型的研究和开发。
2024年底,DeepSeek就发布了第一个模型叫DeepSeek V3,当时美国AI大佬就炸锅了,称之为“神秘的东方力量”。
2025年1月,仅仅过了不到1个月,DeepSeek再次发布新模型DeepSeek R1,正式火爆出圈。
大模型说起来很高端,落地后就是每个人都能使用的APP(也有网页端)。就像当时Kimi和豆包被纷纷下载,DeepSeek也被一顿“薅羊毛”,老外甚至用得更起劲,DeepSeek在美区苹果App Store免费榜直接飚升至第一名。
要知道,国内大模型并不少:字节豆包、月之暗面Kimi、阿里通义千问、百度文心一言、讯飞星火、腾讯混元等等,个个发展得不错,但大部分都没能给美国科技界带来压力,凭什么DeepSeek就有威胁性?
相关解读很多,我就从自己角度来讲讲看,可供参考。
第一,质量绝对过关,评分基本上不输给OPENAI。
不多啰嗦,直接看下面这张图,第一根深蓝色是DeepSeek R1模型,第二根灰色是OPENAI o1模型:
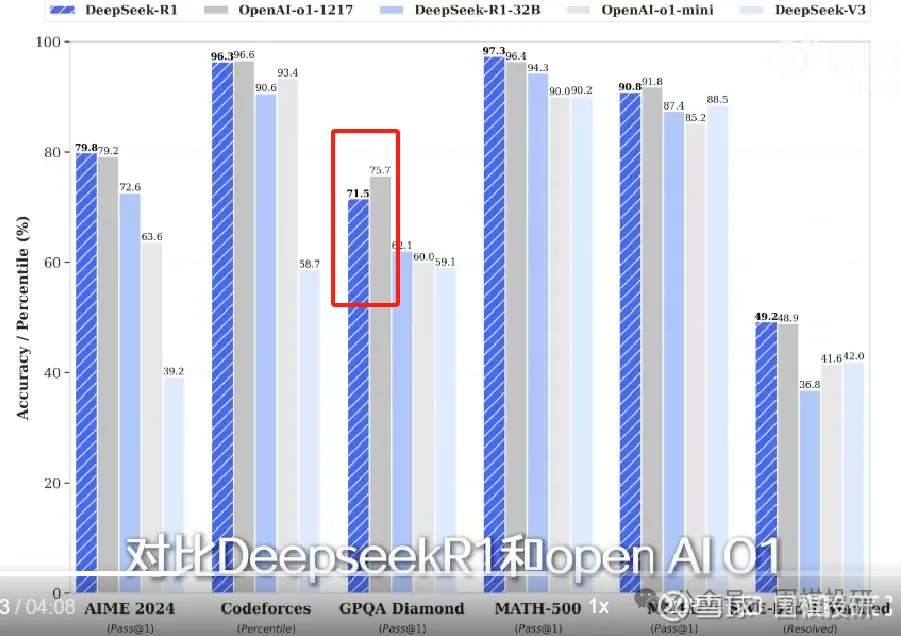
美国OPENAI算是世界级标杆,面对如此强敌,DeepSeek能做到只有1个指标略显逊色,其他都能齐平甚至超越,足以证明实力雄厚。
第二,千言万语,便宜就是硬道理。
如果有了解汽车,DeepSeek就是大模型界的比亚迪(或小米),如果不了解也无妨,更通俗些,DeepSeek就是大模型界的“拼多多”。
还是和“老大哥”OPENAI相比:
OPENAI收取每百万输入词元15美元和每百万输出词元60美元;
DeepSeek收取每百万输入词元0.14美元和每百万输出词元2.19美元。
根本不用管什么输入词元还是输出词元,就记住,DeepSeek要比OPENAI便宜90%以上。
为什么能卖得便宜?成本低啊。OPENAI训练个模型要砸4亿美金,DeepSeek只要550万美金,效果差不多,相当于用拼多多价格做出爱马仕。
差不多的两个软件,一个卖100元,一个卖10块钱,消费者选择过于简单。
这种算不算是内卷?创始人梁文锋在被采访时表示,自己不是有意成为一条鲶鱼,只是不小心成了一条鲶鱼。没想到价格让大家这么敏感,他只是按照自己的步调来做事,然后核算成本定价。
这波确实让他给装到了。
第三,100%开源,等于全世界工程师都在帮忙优化。
可能有朋友不太熟悉软件行业,啥叫开源?做个简单类比:把软件想象成房子,以前这房子的建造图纸只有房子的主人有,其他人想住没问题,但想要知道房子是怎么建的,没门儿。开源,就是房子主人把图纸直接公开了,每个人都能看到怎么设计和建造。
OPENAI是闭源的,如今DeepSeek直接开源,打破了行业格局:卖得便宜就算了,还把业内机密公开,别人再想关起门来收门票,就要被千夫所指。
更绝的是,开源后相当于现在全球无数程序员都在帮着改进系统,像极了当年安卓对抗苹果的剧情。
总结而言,DeepSeek凭借着好东西+好价格+公开透明(越来越像价值投资),一举震惊了全球科技界。
美国AI科技初创公司Scale的创始人亚历山大(这个名字还挺应景)更是直言:DeepSeek的AI大模型发布可能会“改变一切”,让美国在人工智能竞赛中的领先地位受到挑战。
当然,值得庆贺是一方面,但还不至于自满,比如处理超长文本、多模态能力(语音交互)、专业领域优化、训练数据等各方面,DeepSeek以及国内其他大模型都和OPENAI仍有差距。
好戏才刚开始,但至少证明了一件事:在AI这个世界级牌桌上,中国玩家终于不再是看客。
我这两天也用了DeepSeek,确实不错,尤其输出内容特别有逻辑性。模型里有个选项叫“深度思考”,就是把大模型是怎么回答问题的过程,给你展示出来。
这个有点厉害,至少在之前任何大模型里都没见到过,我截个图给球友们感受下,灰色部分就是大模型深度思考的过程:
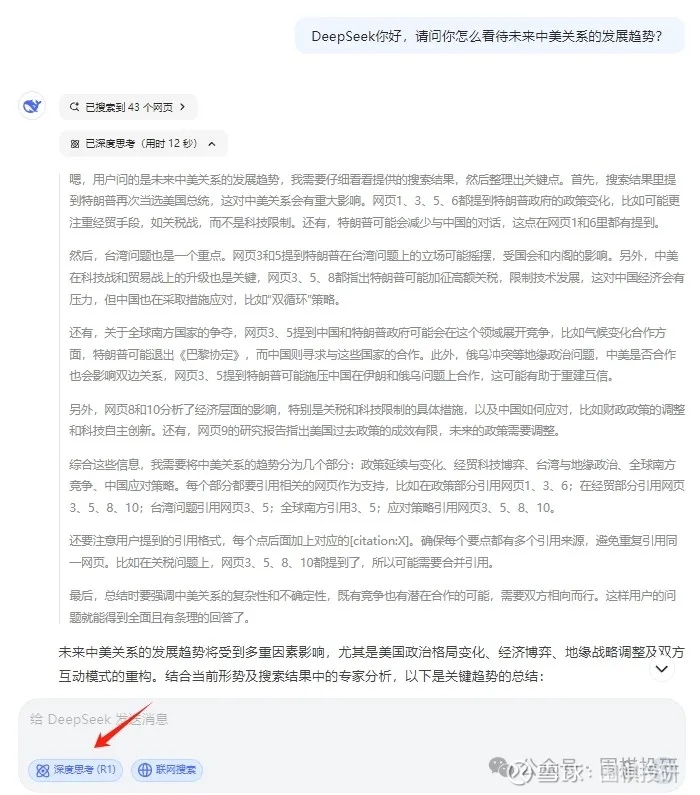
大家如果有兴趣,春节期间没事也可以尝试着用用,到时候有啥好玩的模式或者用法,一起多探讨,我想肯定会很有意思。
至于投资端,短期明显是题材概念,不是我所擅长的能力圈范围,长期肯定看好AI人工智能大趋势。以及,我觉得算力依然稀缺,原因是大模型搞得越高效,AI应用的需求就会越多,到时候算力总盘子就得增加。
就像现在软件效率都很高,但手机和电脑的内存却是越来越不够,因为需求在不断提升。记得以前手机内存64GB就足够,现在新手机都已经提升到1TB内存。
差不多就是这些内容。
近期科技领域不断传来好消息,人工智能有豆包和DeepSeek,人形机器人有宇树,新能源车更是碾压,全球科技创新和高端制造都有国内企业的身影,很为祖国而骄傲,也要致敬这批优秀的创业者和企业家。
#人工智能# #大模型# $金山办公(SH688111)$ $科大讯飞(SZ002230)$ $天孚通信(SZ300394)$ @雪球创作者中心
特别申明:本文内容仅供读者参考,不作为任何投资建议;股市有风险,投资需谨慎。






 首页
首页 微信公众号
微信公众号
 证券之星APP
证券之星APP





