

(原标题:AI应用的现状和难点讨论)
看了很多讨论AI应用的帖子,大部分都是在凭空YY,缺乏对基本概念的认知,单独写一篇介绍下一些基本的概念,包括大小模型到底是啥、AI在工业领域应用中的构建模式以及难点和瓶颈。
我是觉得只有对以上问题有初步认知后,才能在题材炒作中寻找潜底的真龙。
大模型: 大模型通常指具有大规模参数(数千亿甚至万亿)和复杂计算结构的机器学习模型。这些模型通常由深度神经网络构建而成。大模型的设计目的是为了提高模型的表达能力和预测性能,能够处理更加复杂的任务和数据。
大模型的特点是具有强大的泛化能力、支持多模态(文本、语音、图像),缺点是存在幻觉(训练数据的不可靠,导致一本正经地胡说八道)、训练成本高(数据和算力)。
常见的如Chat GPT是大语言模型(从Chat GPT-4开始支持图像数据输入)、Sora是视频大模型。
小模型: 小模型的概念相反,指参数较少、层数较浅,对计算资源和存储需求较小的模型。小模型的设计目的一般是为了解决特定数据场景下特定的业务问题。
小模型的特点是特定场景精度高、易于训练和快速部署,缺点是泛化能力弱(换个场景或数据源就需要重新训练)。
传统的机器学习模型如逻辑回归、决策树以及传统神经网络模型都是小模型。
相同点:目前的技术水平下,大小模型都是基于概率分布的推测,从小模型的predict label到大模型的predict next token,本质是一样的,理解了这点,就能理解AI应用的底层逻辑。
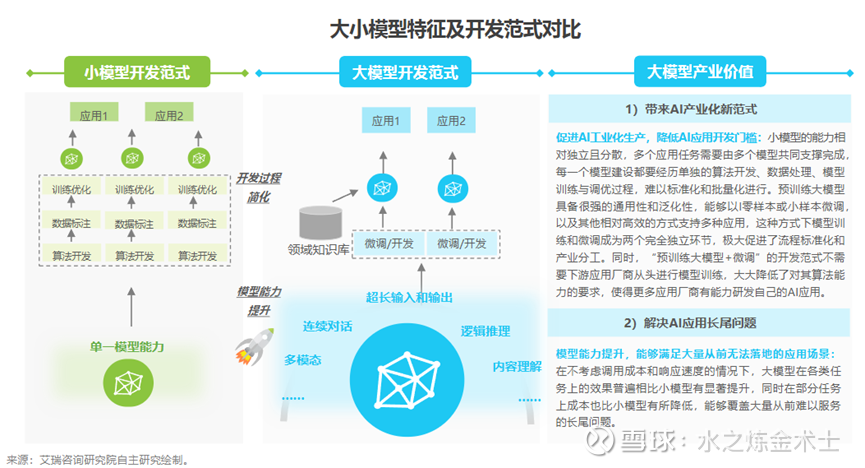
标志性事件:
Open AI发布ChatGPT之后标志大模型时代的到来。在没有大模型之前,AI算法通常需要针对特定的任务和场景进行设计专门(小模型),但人们对“智能”的期望是能够适应多种任务和场景,大模型的出现跨越了小模型的这一局限性,大家看到了人类社会走向AGI的曙光(Artificial General Intelligence 通用人工智能),大模型有望带来“基础模型+各类应用”的新范式。
AGI的常见能力包括推理和解谜,计划和学习,用自然语言交流。核心标志之一是能够通过图灵测试(让受试者们与机器非面对面纯文本形式交流5min,若有30%以上受试者无法区分对面是人还是机器即通过图灵测试)。在对ChatGPT3.5的测试中,有超过半数的人无法区分。
大模型推出以来,国内的厂商也陆续推出号称自研的大模型,但实际上出于成本的考虑很大一部分还是使用开源大模型为底层模型(如Llama)。
从技术领先程度来看,目前肯定是闭源(Open AI为代表)强于开源(Meta的Llama),Llama2约等于ChatGPT3.5。之前看张小珺对朱啸虎采访时朱也提到,这里面存在沉没成本的风险,假如你投钱投人对标ChatGPT4.0去做,做了2年临发布了,啪Llama4 5开源了。商人的视角来看这样没错,但对于愿意推动技术发展的偏执者(比如杨植麟)我还是由衷敬佩的。
还是说回AI应用,在此我们主要讨论下图第三象限的内容(即潜能挖掘类),这个象限是未来AI应用需求的重要潜力点。之前我在第四范式的那篇里也说到了,这些行业目前数字化水平低、AI应用没有太好的土壤。但国家层面对新质生产力的需求一定会催生这些行业的变革,目前已经可以从政策层面看到端倪。
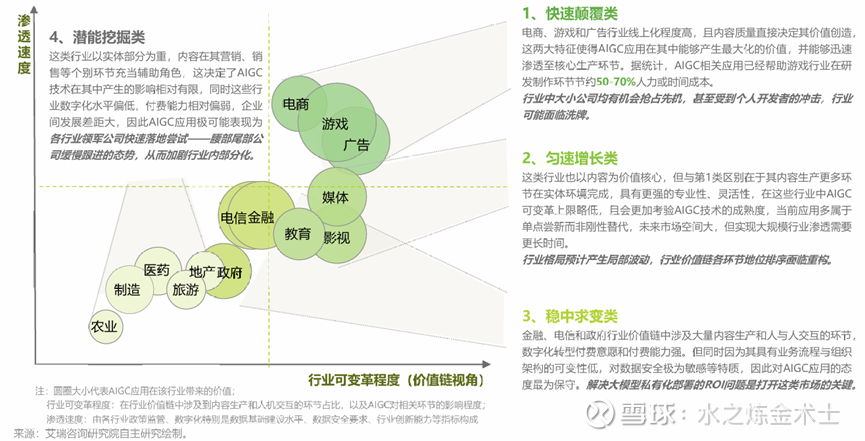
第三象限中,我通过我比较熟悉的制造行业来进行说明(其他行业可以横向类比),我国制造行业AI普及率不到11%,同一数据在欧洲、日本、美国约为30%,我国存在巨大的空间。
AI应用我们分大小模型来看,大模型和小模型目前在工业领域不同场景的应用呈现U型和倒U型分布:
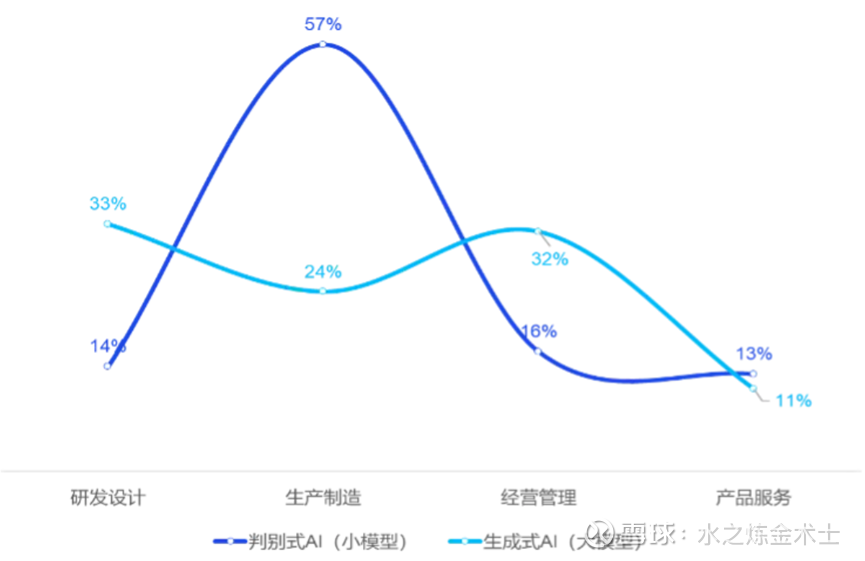
总的来说,对于容错率低、精度要求高的场景(产线检测等)用小模型居多,对于通用属性较强、容错率高的场景(如编写代码、CHAT BI智能图表等)大模型更加好用。
大模型的成本和能力问题不足以完全取代小模型。所以,大小模型在AI应用中会是协作而非替代的关系。协作主要体现在以下两个方面:大模型的生成能力可以帮助小模型生成大量可靠标注数据(效果比传统上采样要好);大模型可以在工作流中通过Agent等方式调用小模型,兼顾精度和灵活性。
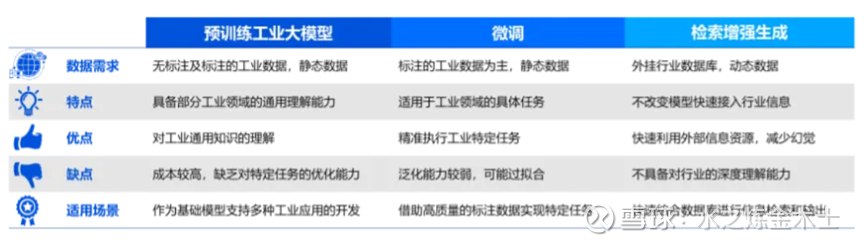
工业大模型或行业大模型最近哪家公司都在提,是PPT吹牛逼还是真货大家可以了解模型构建的几种方式后自行辨别。构建工业(行业)大模型有以下几种方式:
1. 预训练工业大模型:像开发GPT-3/GPT-4、LLaMA1/LLaMA2一样,利用巨量、高质量的工业通用知识数据从头自己搞,最大程度满足工业场景的需求,这需要巨大的算力资源和成本,绝大部分制造企业无法负担也没这动机(我司是个千亿上市制造企业,很重视AI,但也完全负担不起)。
2. 微调:以一个已经预训练完成的通用或者专业大模型基础上,结合工业领域特定的标注数据集进行进一步的调整和优化,从而使模型能够适应具体的工业场景需求,更好地完成工业领域的特定任务。这是目前行业大模型的主流做法。
3. 检索增强生成:检索增强生成模式是指在不改变模型的基础上,结合行业领域的数据、知识库等,为工业场景提供知识问答、内容生成等能力。这个成本最低,但应用场景最有限。(举个例子,我们公司里利用GPT4.0的接口,工程师自己构建产线知识库(产线质量缺陷工单)和prompt(提示词),通过对话迅速生成产线质量报告)。
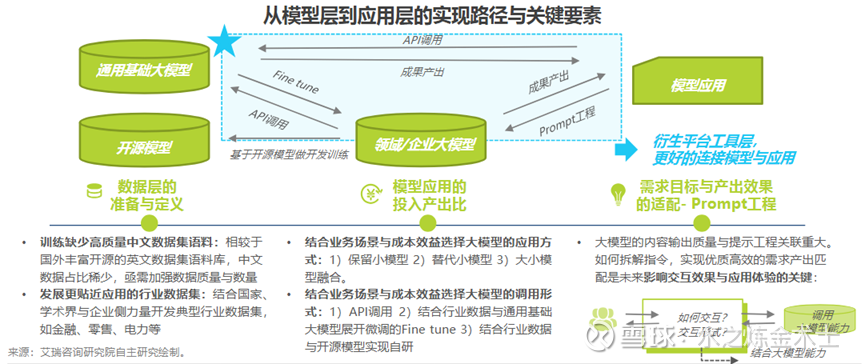
如果碰到不谈私域数据而宣传自己家大模型可以适配各个行业的公司,可以拉黑了,大模型很强大,但不是神,它本身就是基于数据和概率分布给出输出的工具。
上面讲了,精度高容错低的场景一般需要小模型(自动驾驶、产品缺陷检测),除此之外,大模型适用的场景其实也不少:
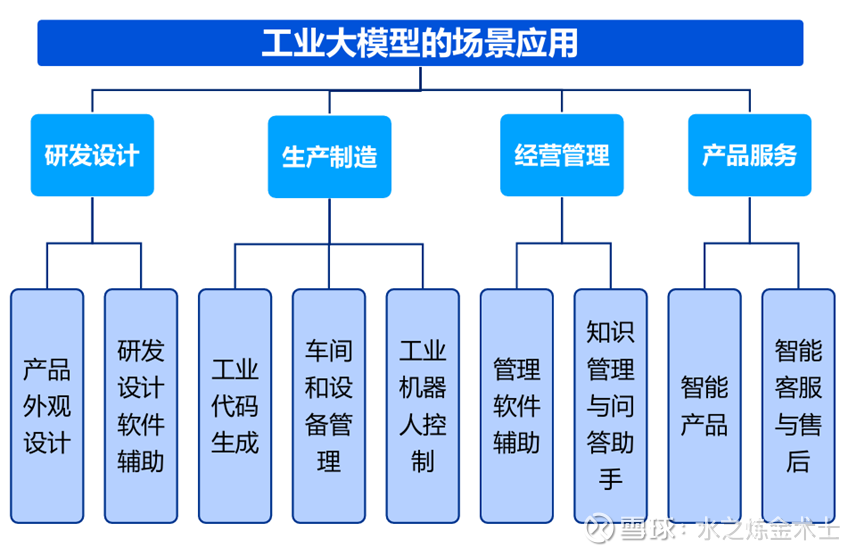
最后总结下AI应用在工业领域的难点和挑战。
小模型就不说了,只能解决点对点问题。而工业大模型或者其他行业大模型面临的挑战其实都类似:数据质量与安全、可靠性和响应速度、经济性。
数据层面来看,理想情况下,To B 的AI应用公司要做出一个适配于某行业的垂直大模型,必须有能代表行业通用知识和业务特性的高质量数据集。行业通用知识还好说,互联网可以获取,但业务强相关的数据大部分被企业自身掌握(如工艺 参数、配方、客户信息),涉及到企业Know-How,基本没有外泄的可能。
并且制造企业数字化程度低,数据基建不足,缺乏AI应用的土壤。
可靠性和响应速度来看,大模型能力不足,这部分问题只有通过Agent将大模型和小模型配合起来才能解决。
经济性来看,主要问题在于投入产出比低,大模型的训练和微调、以及数据安全问题带来的企业私有化部署需求都带来了高昂的成本。这些使得投入产出比低,企业缺乏动机,难以落地。

无论是大模型还是小模型,或者说AI应用,本质上还是解决X通过f(X)到 y的问题,关键点在于构建f(X)的投入产出比,即是否能指数级提升效率以及构建f(X)成本的关系。
众多AI应用公司的f(X),应该成为大家考量的关键因素之一。对于这个同质化严重的赛道,销售能力和创始人特质也是我很看重的要素。
目前的技术水平下,大小模型都是基于概率分布的推测,而AI领域的终极目标之一,是建立一个完整、准确、通用的世界物理模型和超越人类、能够自我学习进化的智能体,目前看依然任重而道远。
$开普云(SH688228)$ $第四范式(06682)$ $Applovin(APP)$






 首页
首页 微信公众号
微信公众号
 证券之星APP
证券之星APP




