

(原标题:快手发布多模态大模型Keye-VL-1.5 8B性能领先、视频理解能力更强)
近日,快手正式发布多模态大语言模型Keye-VL-1.5-8B。与之前的版本相比,Keye-VL-1.5的综合性能实现显著提升,尤其在基础视觉理解能力方面,包括视觉元素识别、推理能力以及对时序信息的理―表现尤为突出。Keye-VL-1.5在同等规模的模型中表现出色,甚至超越了一些闭源模型如GPT-4o。

创新性提出慢快编码策略 兼顾性能与成本
为了在短视频理解任务中同时实现高准确性与高效率。Keye-VL-1.5 创新性地提出了慢快编码策略 (slow-fast),该策略设置慢通路处理快速变化帧(低帧数-高分辨率),快通路处理静态帧(高帧数-低分辨率),从而在节省计算资源的同时保留关键信息。
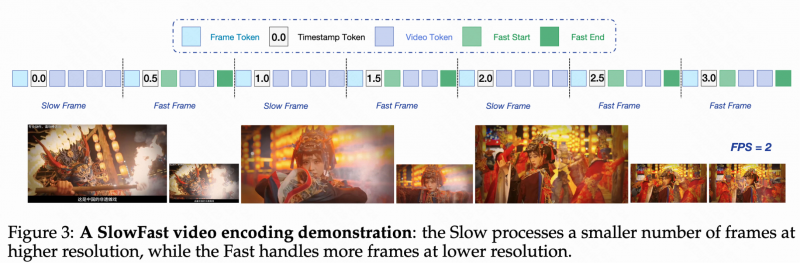
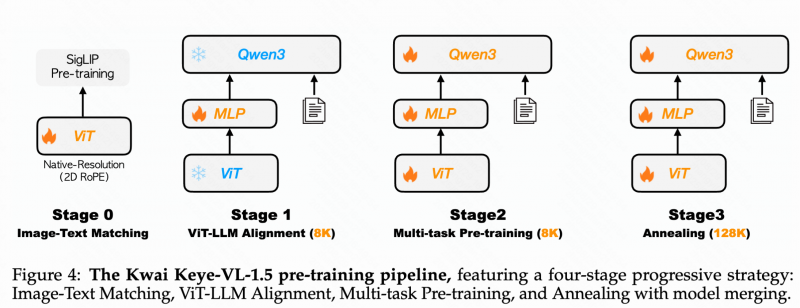
渐进式四阶段预训练方法 大幅增强视频理解能力
Keye-VL-1.5采用四阶段渐进式训练流水线,以系统化方式提升模型性能。首先,在视觉编码器预训练阶段,使用SigLIP-400M权重初始化ViT,并通过SigLIP对比损失持续预训练以适应内部数据分布。第一阶段重点优化投影MLP层,实现跨模态特征的稳固对齐;第二阶段解冻全部参数进行端到端多任务预训练,显著增强基础视觉理解能力;第三阶段进行退火训练,利用高质量数据微调模型,弥补上一阶段中高质量样本接触不足的问题,同时将序列长度扩展至128K、调整RoPE逆频率配置,并引入长视频、长文本和大尺度图像等长上下文数据。
最终,通过同质-异质融合技术对不同数据混合比例下的模型权重进行平均,减少固定数据比例带来的内在偏差,在保持多样化能力的同时提升模型的鲁棒性。
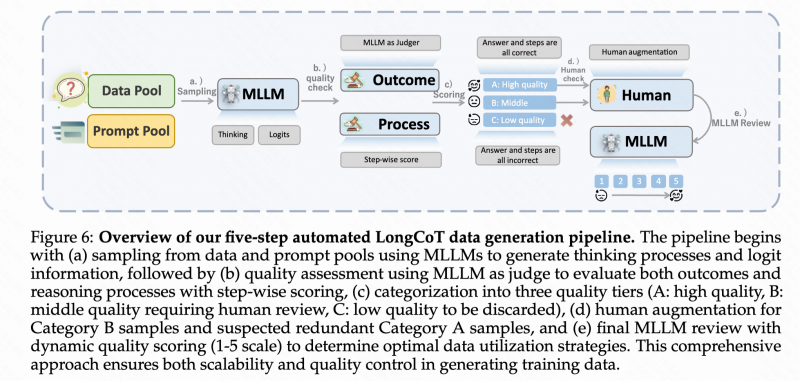
构建一套完整的后训练流程 全面提升推理能力与人类偏好对齐
Keye-VL-1.5构建了一套系统化的后训练流程,包含四个核心阶段:监督微调与多偏好优化、长链思维冷启动、迭代通用强化学习以及对齐强化学习。该流程进一步融合了由快手Keye团队提出的五步自动化数据构建流水线,并依托GSPO算法对通用强化学习与对齐阶段进行迭代优化,显著增强了模型的推理能力,同时更好地与人类偏好实现对齐。
在多项权威评测中,Keye-VL-1.5-8B表现突出,在MMMUval、OpenCompass等大型多模态评测中达到同类规模最佳成绩,在Video-MMMU视频理解评测中取得66分,展现出领先的视频语义理解与技术落地潜力。
此外,Keye-VL-1.5-8B目前已在Hugging Face、GitHub等平台开源,相关技术报告同步发布,推动多模态大模型技术共享与生态共建。
快手Keye团队表示,该模型依托快手在短视频领域的深厚积累,在视频时序理解、场景推理与指令跟随等关键能力方面优势显著。未来,Keye-VL将持续推进多模态大模型在视频语义理解与生成领域的探索与应用。
本文来源:财经报道网



 首页
首页 微信公众号
微信公众号
 证券之星APP
证券之星APP

