

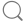
| ָ�� | ����ʱ�� | ����ֵ | ͬ������ |
| GDP | 2026��һ�������� | 695704 | 4.7% |
| CPI | 2026��06�·� | 101 | 1% |
| PPI | 2026��06�·� | 104.1 | 4.1% |
| M2 | 2026��06�·� | 3567108.43 | 8% |
| ���� | ���¼� | �ǵ� | �ǵ��� |
| Ӣ����Ԫ | 1.3301 | 0.0012 | 0.09% |
| ŷԪ��Ԫ | 1.1378 | 0.0010 | 0.09% |
| ��Ԫ��Ԫ | 163.7228 | -0.0250 | -0.02% |
| ��Ԫ��Ԫ | 1.4116 | -0.0009 | -0.06% |
| ��Ԫ���� | 0.8186 | -0.0007 | -0.09% |
| ���� | ���¼� | �ǵ� | �ǵ��� |
| ȼ������ | 3495 | -234 | -6.28% |
| NYMEXԭ�� | 81.56 | -1.05 | -1.27% |
| NYMEX���� | 3.1564 | -0.0132 | -0.42% |
| NYMEXȼ�� | 3.9872 | -0.0188 | -0.47% |
| ԭ������ | 532.6 | -32.4 | -5.73% |



 �Ź��ں�
�Ź��ں�
 ֤ȯ֮��APP
֤ȯ֮��APP






